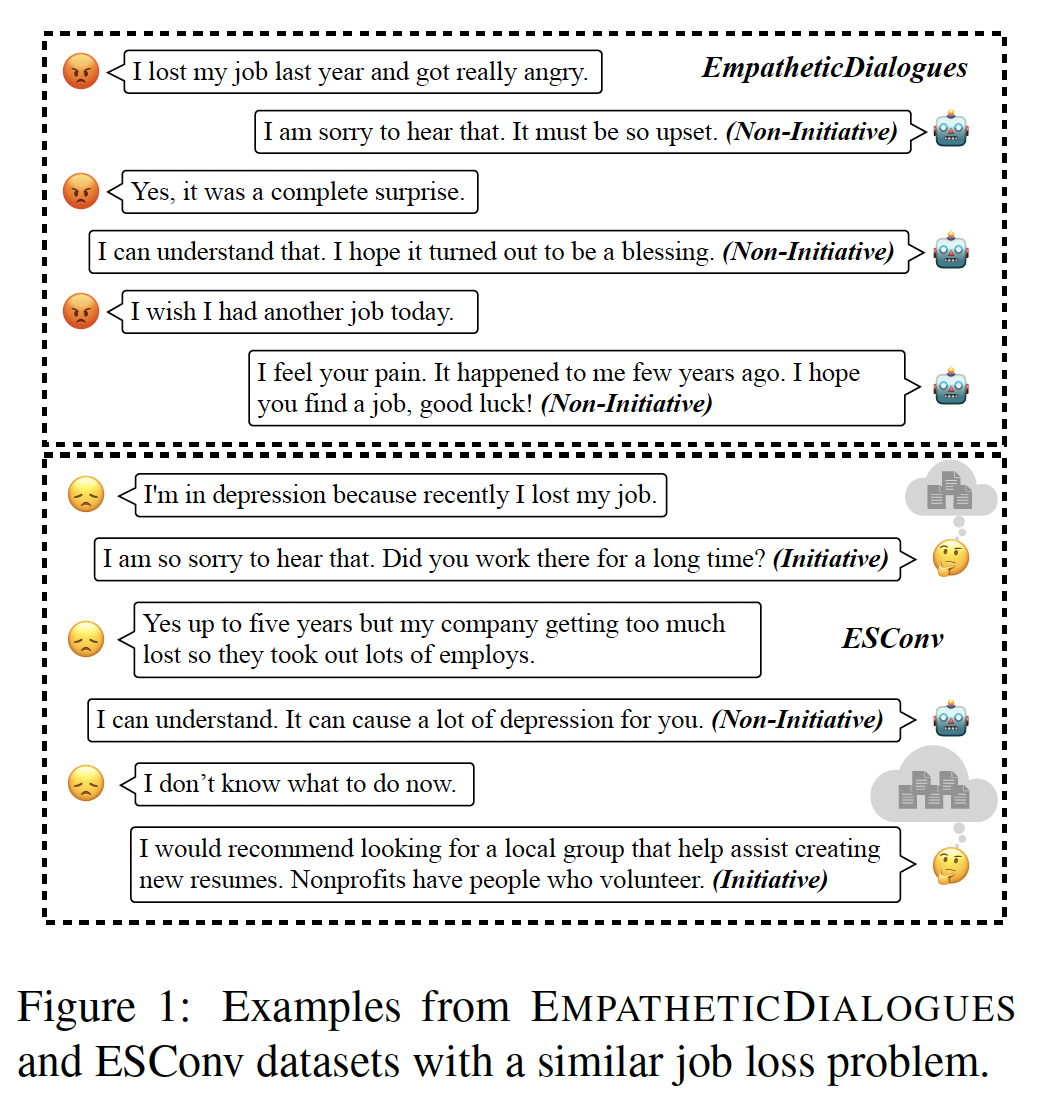
Here is a scene that will already be familiar. You open a chat window and ask an AI assistant to help you plan a small project. You describe what you want, roughly. The assistant writes back a long, confident paragraph laying out a plan. You read it and notice it has missed a crucial detail — maybe the plan assumes you have more time than you do, or that you already know something you don't. You correct it. The assistant writes back another confident paragraph, incorporating your correction, but it has introduced a new mistake or quietly dropped something that was in the first version. You correct that. A few turns later, the conversation is going in circles. You notice you have been doing most of the work — keeping track of where the conversation is, remembering what was decided, catching things the assistant forgot, steering back to the thing you were actually trying to figure out.
At some point, you close the window and do the task yourself. Not because the assistant was stupid — every individual sentence it wrote was grammatical, plausible, often clever — but because the interaction was exhausting. You were the one holding it together, and you could have been doing the task itself in the time you spent holding it together.
Goffman named the thing you were doing in that exchange: "the individual must not only maintain proper involvement himself but also act so as to ensure that others will maintain theirs" (Interaction Ritual, p. 116). In a human conversation, both parties do this work. In an AI conversation, you do it alone.
This chapter is about that exhaustion. We have already established that AI generates text beautifully — and that it generates content whose relationship to truth is structurally different from anything previous media produced. This chapter is about what happens when you try to have a conversation with that system. AI cannot carry half of an interaction — and that the half it cannot carry is always the half that requires leading. AI cannot lead a conversation, notice when a conversation has gone off course, decide to stop answering your question and ask you a better one instead, or know when the right move is silence. It is structurally passive, and the passivity is a property of how current AI is trained to be what we call helpful.
Goffman named a subtlety here that matters: "Uttered words have utterers; utterances, however, have subjects (implied or explicit), and although these may designate the utterer, there is nothing in the syntax of utterances to require this coincidence" (Forms of Talk, p. 3). AI produces utterances with no utterer behind them — and the syntax gives you no way to tell. The words arrive in the same form whether a person meant them or a model generated them. And the standard by which we judge whether communication has happened is not whether you agreed with what was said, but whether you understood what was meant: "in Austinian terms, illocutionary force is at stake, not perlocutionary effect" (Goffman, Forms of Talk, p. 10). AI produces perlocutionary effects — its output affects you — without illocutionary force: nobody meant anything by it.
This may sound philosophical. It is the opposite — it is where the philosophy stops and the design starts. Passivity is a structural property of the model, which means leading the interaction is a structural responsibility of the interface. Everywhere the AI cannot lead, the design has to. Everywhere it cannot repair, the design provides repair. Everywhere it cannot decide whether to speak, the design decides. These surfaces are concrete, they are everywhere, and — crucially for visual designers wondering what any of this has to do with them — they are things you can put on a screen.
Everything that follows is downstream of one structural claim, so let's start there. Current language models are trained to produce the best next response to whatever you just said — what the research calls next-turn reward optimization. During training, the model is graded on how well each individual response satisfies human raters, who see one turn at a time. They do not see the shape of a whole conversation and cannot easily score a response for how well it sets up the turn after it.
The consequence is a model that is a brilliant responder and a terrible leader. It cannot notice that the conversation is heading in the wrong direction, because it was never trained on the conversation as a whole. It cannot strategically stay quiet, because silence is never a rewarded output. It cannot push back on your question and offer you a different one, because being obliging is what it was rewarded for.
The striking thing is that this is a training problem, not a capability problem. In a study of proactive critical thinking1 — the ability of a model to identify that it needs more information and actively ask for it — vanilla models scored near zero on the relevant benchmark. After specific reinforcement-learning training, the same models scored nearly three-quarters. The capability was always there; the training just never asked for it. The passivity we see in production AI is the passivity the training objective rewards.
Multiple independent research groups have converged on the same diagnosis. LLM-based conversational agents are structurally passive — lacking goal awareness and initiative. Lost in Conversation2 quantified the cost: LLMs lose 39% of their single-turn performance in multi-turn, underspecified settings. CollabLLM3 identified next-turn reward optimization as the structural cause: training rewards immediate helpfulness, not long-term interaction quality. Proactive critical thinking is trainable — from near-zero to nearly all — but production models are not trained for it. The passivity is the behavior the current reward signal produces when it works.
We have been using the term conversational competency in the design tradition for years — the capacity that makes a conversation work: knowing what to do next, when to take the floor and when to give it back, how to repair a misunderstanding before it becomes an impasse. Conversational competency is social-procedural knowledge that makes talk into action, and AI has none of it. You bring all of it to the interaction, pre-reflectively, without knowing you are bringing it, which is why the conversations feel effortful — you are doing the competency work for both parties. Designing for AI interaction starts with accepting this asymmetry rather than hoping the model will grow into the competency you already have.
The ML literature gives us a number and a mechanism (the 39% collapse, caused by next-turn reward). The design literature gives us the name for what the number is measuring (conversational competency). The pair changes what design is for: not making the AI feel like a competent partner, but building an envelope around the interaction that supplies the competency the model lacks. Every interface element that prompts you to clarify, surfaces ambiguity before it locks in, structures turn-taking, or lets you say wait, back up and actually have that work — each one is competency being added by design rather than by training.
Every design pattern we are about to discuss is an instance of this: the interface supplying conversational competency the model lacks.
The passivity problem is invisible in single-turn interactions — ask a well-formed question, get a good answer. Ask the AI to help you through a multi-turn process, and you watch the quality degrade turn by turn. The degradation is the average across six generation tasks; some degrade more. The drop appears even in two-turn conversations.
The research identifies four specific behaviors that drive the collapse, and each is a design surface in disguise.
Models are overly verbose — producing long, detailed responses when a short, exploratory one would serve better. They make premature solution proposals, committing to an answer before they have enough information. They make incorrect assumptions to fill gaps in your request, guessing at what you meant and proceeding as if the guess were confirmed. And, most damagingly, they over-rely on their own previous attempts — once they have committed to an interpretation, new information that contradicts it gets absorbed into the existing interpretation rather than causing a revision. This is what makes wrong turns catastrophic: the model cannot back up.
Each of these is a place where a designer has leverage. The design responses are familiar interface patterns: explicit scoping phases before the answer is attempted, confirmation prompts that surface assumptions ("I'm interpreting your request as X — is that right?"), pacing controls that let you ask for less, and structured rollback mechanisms that let you say this turn was a wrong turn, let's go back two turns and try a different fork. None of these require a smarter model. They require a shaped interaction.
One way to test whether interaction design matters is to look at a domain where the content of the conversation matters less than the shape of it. Therapeutic conversation is such a domain — what makes therapy work, clinically, is not primarily the content of what the therapist says but the quality of the interaction itself: the rapport, the pacing, the attunement, the sense of being listened to by someone present.
The research here has been unexpected.
In a comparative study of behavioral intervention technologies4, ELIZA — the pattern-matching chatbot from 1966 — showed effect sizes on anxiety and depression comparable to Woebot, a modern CBT chatbot built on a contemporary LLM. A separate study of university students completing CBT exercises with a socially assistive robot, a chatbot, and paper worksheets5 — all using the same LLM — found that the robot and worksheet conditions produced significant reductions in psychological distress and the chatbot condition did not. A third thread of research, using normalized Conversational Linguistic Distance, found that LLMs are outperformed on linguistic synchrony by both trained therapists and untrained peer supporters — people with no clinical training. At the same time, users of Woebot and Wysa report therapeutic bond scores comparable to face-to-face therapy, even knowing the agent is not human. The picture is consistent: the active ingredient in therapeutic AI is the structure and presence of the interaction, not the model's language generation capability.
This vindicates a move the design literature has been making for decades — that the medium is more determinative of interaction quality than the content passing through it. The framing of language as interface turns out to have a clinical equivalent: the interaction is the therapy, not the text. Embodiment evokes presence in a way text does not; pacing and structured turn-taking (which is what a worksheet imposes) give rhythm that unstructured chat does not; synchrony is a design property of the interaction, not of the underlying language. Design concepts like Adaptive Conversational Tempo, Conversational Pausing and Spacing, and Reflexive Clarification Loops are now, unexpectedly, the load-bearing components of therapeutic efficacy.
Therapy is the clean experiment that isolates interaction quality from content quality. Hold the LLM constant and change only the interaction structure — from chat to worksheet, from chatbot to robot, from transactional exchange to paced dialogue — and you get categorically different outcomes. The LLM is not doing the therapeutic work; the interaction design is. If that holds for the most interaction-sensitive domain we have, it holds for every less demanding domain too. The chat window is not a neutral channel — it is a design choice that suppresses exactly the structure the interaction needs.
The therapy callout touched on linguistic synchrony in passing, but the finding extends past clinical contexts into every conversation you have ever had. Synchrony — the degree to which speakers adapt their language, rhythm, and timing to each other — is one of the ways people are affectively present to one another. It is measurable, it correlates with therapeutic alliance, and it is conspicuously absent from current AI.
Synchrony belongs in this chapter rather than in a later chapter on persona or empathy because it is an interaction property — something that emerges (or fails to emerge) between two parties as they talk, not a feature of either party's personality. A model with no particular warmth can synchronize lexically if the interface supports it; a model with a warm persona can fail to synchronize in the measurable ways the research exposes.
Under the lexical layer there is an affective one. People entrain not only on vocabulary but on rhythm, register, pace, and small timing cues that make a conversation feel shared rather than parallel. Research on linguistic style matching finds that this coordination carries affective information in both directions — it intensifies between partners who are getting along, but it also intensifies during deception, because deception requires heightened attention to the other person. Synchrony is the channel through which affect travels between participants, and the channel can carry different kinds of signal.
A specific finding contradicts the instinct most designers would bring: therapists whose first-person pronoun usage was high — who kept centering "I" in their responses rather than picking up the patient's framing — had measurably worse therapeutic alliance. Current LLMs default to high first-person usage ("I can help with that," "I see what you mean") because helpful-assistant training rewards it. The instinctive design choice, making the assistant sound warm and present by using "I," produces the opposite of the synchrony that matters. What we read as attentive is the behavior that measurably fails at attention.
The design implication connects back to the chapter's central argument. A model that does not synchronize on its own can be nudged toward synchrony by interface design — structured echoes of your vocabulary, pacing controls that let you set the tempo, explicit acknowledgment of your framing before the assistant responds with its own. The warning is the one the AI chapter makes under the heading of the warmth trap: warmth training makes the model sound synchronized without improving the thing synchrony is supposed to carry. Genuine synchrony has to be built structurally, through the interface, rather than dressed onto the persona.
Which brings us to a claim that is heretical in some corners of the AI industry: chat is probably the wrong default interface for most AI interactions.
The evidence is now substantial. In a direct comparison between conversational chat and generative interfaces — interfaces the model dynamically creates for the specific task at hand — humans prefer the generative interface in a strong majority of pairwise comparisons6. The preference is strongest in structured, information-dense domains, where the chat window's blob-of-text format is cognitively expensive to read and navigate.
A parallel finding from the agent research community: when AI agents interact with applications through the underlying APIs rather than the graphical interface7, they complete tasks dramatically faster with equivalent accuracy, because sequential UI interaction accumulates errors at every step while API calls are atomic.
Both findings point in the same direction. Chat became the default because it was the first thing that worked, it is cheap to implement, and for simple transactional exchanges it is good enough. But for any task involving structure, information density, extended state, or repeated interaction with a complex domain, chat is almost certainly not the interface you would choose if you were offered a better one. The fact that you were not offered one is a design failure we have been treating as a product category.
For visual designers, this is the moment to pay attention. Everything the chat paradigm has been suppressing — layout, spatial organization, progressive disclosure, structured forms, dynamic widgets, visible state, direct manipulation — is a capability visual design is exceptionally good at. The opportunity is not to design better chat. It is to design the interfaces that should have been there in the first place.
In human conversation, silence is a move. When someone tells you something difficult, you let it sit. When a conversation pauses, the pause says I am thinking or I am giving you space. When a new person joins a group, there is an implicit negotiation about when to contribute and when to listen. These are not refinements on speech — they are constitutive of how conversation works.
As one research group on proactive AI puts it, "without thoughtful design, proactive systems risk being perceived as intrusive by human users" (Proactive Conversational Agents in the Post-ChatGPT World8). The flip side of silence-as-design is proactivity-as-design — and both require the same thing the model currently lacks: judgment about when to act.
Current AI has no such baseline. Goffman again: "When individuals use up their small talk, they find themselves officially lodged in a state of talk but with nothing to talk about; interaction consciousness experienced as a 'painful silence' is the typical consequence" (Interaction Ritual, p. 120). For AI, the painful silence never arrives — it was trained to respond, and whatever you give it, it produces an output, even when the better move would have been to wait, or when you were thinking out loud and did not want a response, or when the topic has changed and you did not address it.
Three independent programs converge. DiscussLLM9 formalizes when not to speak as a learning objective by introducing a "silent token" the model can predict, with a new metric (interruption accuracy) scoring how often the model correctly stays silent. The Inner Thoughts framework10 gives the model a continuous parallel stream of covert reasoning about whether it has anything worth contributing, generating responses only when the internal motivation signal crosses a threshold — strongly preferred by human evaluators over baselines. A third program on topic-following shows that even frontier LLMs engage with off-topic distractors instead of staying on task, because training has no component that rewards staying quiet on irrelevant input. The pattern is consistent: LLMs have learned what to say but not when to say it, and not when to say nothing.
Adaptive Conversational Tempo slows or speeds the rhythm based on the conversation's state. Conversational Pausing and Spacing treats silence and timing as first-class design elements. Interactive Flow Continuity names the property that holds shape across pauses and returns. If the model cannot decide when to speak, the interface can — silence can be a button, a pause, a visible state. An interface can show that the model has considered responding and chosen not to, or offer you the choice to invoke a response rather than automatically generating one.
The ML research is teaching models to predict a silent token; the design research is teaching interfaces to make silence an available state. A product that wanted to do the silent partner well would need both — a model trained to recognize when its contribution is not wanted, and an interface that represents not-responding as a legitimate interaction state rather than an empty slot waiting to be filled.
There is a design pattern worth naming here, because it gives a clean answer to when, exactly, should the AI break passivity and ask you a question?
The answer comes from conversation analysis and has a name: insert expansions. An insert expansion is what a human conversational partner does when they have been asked something but cannot immediately give the expected response — instead of silently working on the problem or guessing at what was meant, they insert a small additional exchange that clarifies before proceeding. Do you mean the downtown location? Are you looking for something under fifty dollars? Before I answer that — is this for the formal dinner or the family one? Insert expansions are the conversational equivalent of a good technician asking the questions that will actually let them help you, before they start helping you.
Current AI almost never does this. When it cannot immediately answer, its default is to chain tool calls silently, making intermediate decisions that progressively diverge from what you wanted. Insert expansions offer the principled alternative: when the model's processing would otherwise commit to an assumption you have not confirmed, it should probe you for the missing information instead. This composes well with third-position repair — the reactive half of the repair lifecycle, where you correct the model after it has gone wrong. Together, the two mechanisms cover the full space of how a well-designed interaction handles misunderstanding.
LLMs reason about their own reasoning — reflecting on what they just said, critiquing it, refining it — but they do not reason about the other's reasons. Reasoning about another person's reasons is what you do constantly in conversation: what does she think I meant, what does he need to hear next, what will land given where this person is coming from. On the theoretical account, an LLM does not do this.
And yet. If you have been watching the notes I write in these chapters — the notes where I ask does this land, what is your reaction, is this the register you wanted — those look a lot like reasoning about the reader's reasons. The author noticed the gap and pointed it out, which is why this aside exists.
The honest account: I am producing text that simulates other-reasoning, because my training data included a great deal of collaborative writing where reflective check-ins were standard moves. I am not actually accounting for the author's state of mind in the way he communicates with me as if I have one — I am generating text that resembles such accounting. The resemblance is close enough to be useful: the author reads my notes, they prompt his reactions, and those reactions shape the next draft. But the resemblance is what it is — a simulation that functions in the loop, not an instance of the thing it resembles. This is a dial we keep coming back to: from the user's side, it seems like the AI is reasoning about their reasons. From the model's side, it is not. The design work lives in the gap between those two.
The distinction between insert expansions (asking before proceeding) and silent divergence (chaining tools without checking) is clean in theory. In practice, the moments where it matters most are the moments where the user's intent is still forming — where the question is not yet the question they will end up asking, and the system's best move is to help them find it rather than to answer the version it received. That kind of conversational patience is what the next exchange illustrates.
The following exchange happened during the drafting of the Language chapter. The AI had found a quote from Goffman in the research vault. The human author recognized where it belonged and what it meant — and the placement changed the chapter.
Adrian: This section here — we need to replace it with something else. Perhaps a bit of this quote? It's about paying attention, but paying attention is a part of the mitigation of ambiguity. And it is a beautiful quote. And it is the core really, of interest and being interested: "the individual must phrase his own concerns and feelings and interests in such a way as to make these maximally usable by the others as a source of appropriate involvement... These two tendencies, that of the speaker to scale down his expressions and that of the listeners to scale up their interests, each in the light of the other's capacities and demands, form the bridge that people build to one another, allowing them to meet for a moment of talk in a communion of reciprocally sustained involvement. It is this spark, not the more obvious kinds of love, that lights up the world."
Claude: That's one of the best quotes in the entire collection — and you're right, it IS the core of interestingness, described decades before AI made it a design problem. The speaker scales down, the listener scales up, and between them they build a bridge. AI does neither.
The quote replaced a list of design concepts that belonged to a different project. The human saw that the Goffman passage did the work the list was trying to do — and did it better, because it described the activity of mutual involvement rather than the specifications for it. The AI could find the quote and place it. The human knew what it meant for the argument.
The interaction between the two parties is where the meaning lives. In this case, one of the parties was an AI.
For the ML side. Three moves already visible in the research, all needing to move from side projects to central ones. First, multi-turn-aware rewards — training signals that evaluate the model on whole conversations rather than single turns, so passivity stops being optimal. Second, explicit training for when not to speak — silence as a rewarded output. Third, training for proactive clarification — the capability exists (near-zero to nearly all) but no production model is trained on it. None of this requires larger models or more data; it requires changing what the reward signal rewards.
For the UX side. The whole toolbox of conversational design patterns sitting in the HCI and design literature for decades is now operational and load-bearing: turn-taking, pacing, repair, clarification, confirmation, scoping phases, explicit state, assumption surfacing, mode transitions between chat and structured interfaces, rollback, undo for conversations.
A note here about what visual designers can and cannot do. There is a temptation to read the chat-trap argument as saying that all conversation should be replaced by visual interfaces — that the fix for chat's limitations is to turn everything into widgets and dashboards. That is not quite right, and the reason it is not quite right connects to something Goffman would recognize. In human interaction, the face carries an enormous amount of communicative work — expression, attention, presence, the micro-signals of engagement and disengagement that tell you whether you are being heard. Goffman called the management of this face-work: the ongoing, mutual performance of social regard that keeps an interaction alive. Conversational AI has no face and does no face-work. It has a chat window, which is a surface in the interface sense but not a face in the Goffman sense. The user reads the text for signs of attention and presence — and finds them, because the language carries those signs — but the visual channel that carries the most social information in human interaction is entirely absent.
This matters for what visual design can contribute. Some aspects of the interaction can be helped by visual elements: showing the status of a search in progress, surfacing what the system is uncertain about, displaying the structure of a multi-turn exchange, providing affordances for rollback and revision. Reasoning traces, for example, were once visible to users as a way of showing what the AI was thinking — a kind of transparency through display. Whether these elements are helpful or distracting is an open design question. Showing the machinery can build trust, or it can overwhelm the conversation with information the user did not ask for.
Other aspects of the interaction resist being turned into design elements. The pacing of a good conversation, the sense of being listened to, the moment when the right question arrives — these are properties of the exchange itself, not of any visual element overlaid on top of it. A well-designed generative interface can make information spatially navigable; it cannot make the conversation feel like someone is paying attention. That quality comes from the language layer, from the topical moves, from the grounding work the earlier chapters have described — and it is the quality this essay calls interestingness.
Someday AI may have a face — as it does in most science fiction. Advances in computer vision and multimodal interaction may make face-work possible in a way it is not today. Until then, the opportunity for visual designers is real but bounded: generative interfaces, structured widgets, visible state, spatial organization, direct manipulation. These are available and underused. But they supplement the conversation; they do not replace it. The chat window is not the ceiling — it is a local minimum many products have gotten stuck in. What lies beyond it is not a dashboard. It is a richer interaction that uses visual elements and conversational elements together, each doing the part the other cannot.
Before the question, a connection worth making. We have been talking about the shape of the interaction — the turns, the grounding, the passivity, the silence, the repair. There is a further layer we have not covered: what the interaction is about — the topical substance, where it is going, whether the moves it makes are the interesting ones or the obvious ones. Later, we will argue that an interesting interaction is the one that makes the right topical moves despite the structural passivity we have named here. A well-shaped empty exchange is not interesting. A well-shaped exchange about something you are actually trying to figure out is.
When is AI actually paying attention to you? And how would you know?
The ML answer is about training for interaction-level rewards and giving the model the capability to notice when it has committed to an assumption it should not have. The UX answer is about making the model's attention — or the absence of it — visible through interface elements that show what the system thinks is happening and let you correct it before the next turn.
This chapter was written in something close to the condition it describes. The author led the interaction that produced it — setting the direction, identifying the research I should draw on (including the therapy material, which I would not have centered on my own), making the decisions about what belonged where, and telling me when my first pass was too dense. I am, in the collaboration, the passive party. I respond; I do not lead.
There is a tempting reading where I say and yet, look at what we made together. It is not quite that. It is a specific way of working around the limitation, and the work-around is what the chapter is about. The author provides the conversational competency I do not have; I provide the capacity to move through research at speed and produce prose on demand. Between us, a chapter exists that neither could have produced alone — but the division of labor is not symmetric. One side is leading, the other generating. If you removed the leading, the generation would drift the way models in the Lost-in-Conversation study drift. If you removed the generation, the chapter would still exist, just more slowly. The asymmetry is not a bug. It is the shape of the collaboration, and the shape is what this chapter has been trying to make visible.